目录
- 元字符
- 贪婪、非贪婪与独占模式
- 分组
- 匹配模式
- 断言
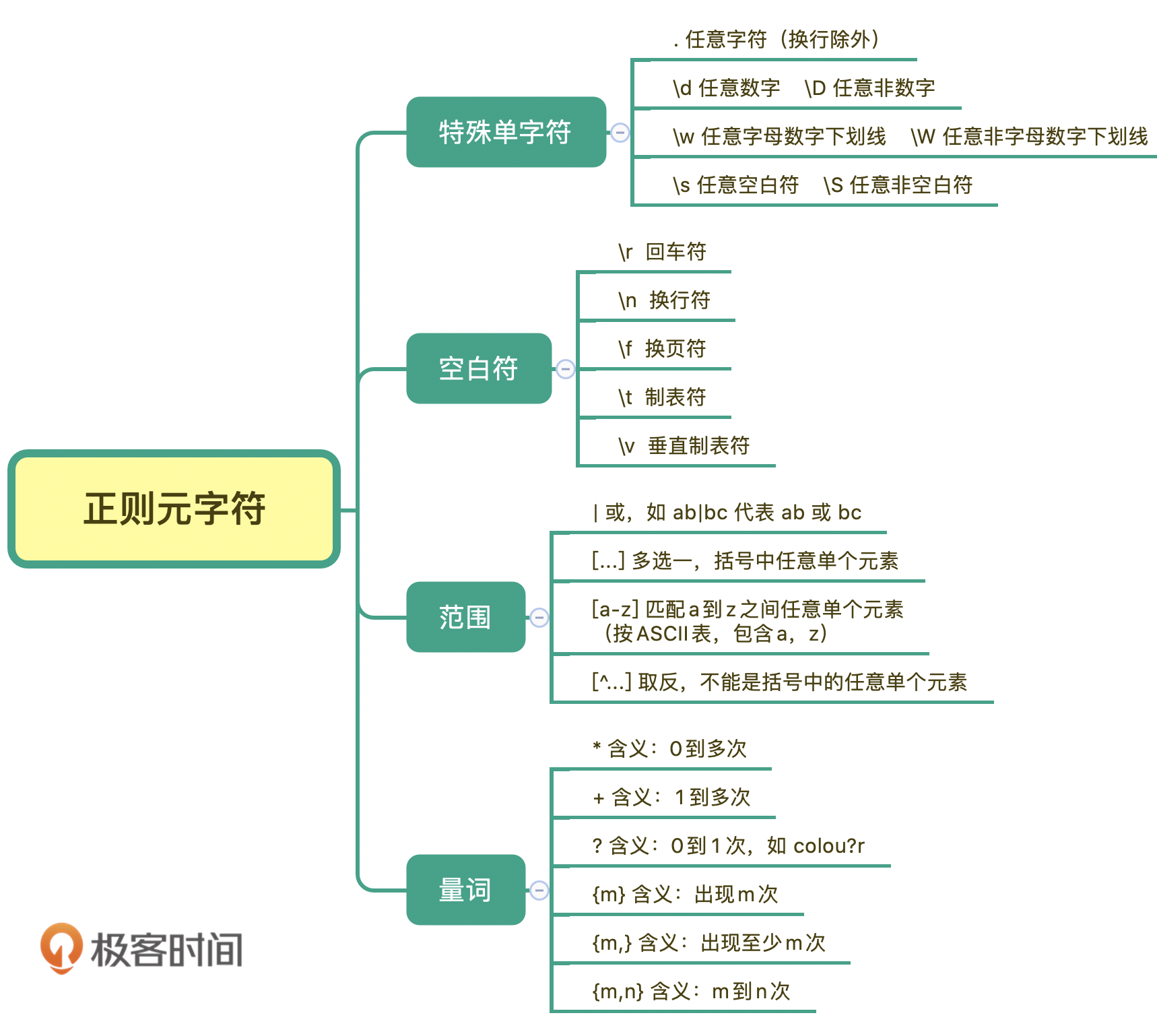
元字符
元字符指的是在正则表达式中具有特殊意义的专用字符。元字符是构成正则表达式的基本元件,正则表达式就是由一系列的元字符组成的。
- 特殊单字符
| 标识 | 含义 |
|---|---|
| . | 任意字符(换行除外) |
| \d | 任意数字 |
| \D | 任意非数字 |
| \w | 任意字母、数字及下划线 |
| \W | 任意非字母、数字及下划线 |
| \s | 任意空白符 |
| \S | 任意非空白符 |
- 空白符
| 标识 | 含义 |
|---|---|
| \r | 回车符 |
| \n | 换行符 |
| \f | 换页符 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \s | 任意空白符 |
平时使用正则表达式时,大部分场景使用 \s 就可以满足需求。
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的机械打字机,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做”回车”,告诉打字机把打印头定位在左边界,不卷动滚筒;另一个叫做”换行”,告诉打字机把滚筒卷一格,不改变水平位置。这就是”换行”(\n)和”回车”(\r)的由来。
换页符(\f)是一种控制字符,用于在打印或显示输出时将当前页面清空,并开始新的页面。换页符的作用是让打印设备或终端在输出内容之前,将整个屏幕或页面清空,然后继续输出接下来的内容,给人一种页面切换的效果。换页符的使用效果主要取决于其使用的环境。在打印环境中,换页符会将打印机的当前页面清空,并开始新的页面输出。而在终端或控制台中,换页符会将终端屏幕清空,然后输出接下来的内容。
- 量词
无论是”特殊单字符”,还是”空白符”,它们都只能匹配单个字符。如果需要匹配单个字符,或者某个部分”重复N次”,或者”至少出现一次”等等,就需要用到表示量词的元字符。
| 标识 | 含义 |
|---|---|
| * | 0到多次 |
| + | 1到多次 |
| ? | 0到1次 |
| m | m次 |
| {m,} | 至少m次 |
| {m,n} | m到n次 |
- 范围
| 标识 | 含义 |
|---|---|
| | | 或,如 a|b 代表a 或 b |
| […] | 多选一,匹配括号中任意单个元素 |
| [a-z] | 匹配 a 到 z 之间任意单个元素 |
| [^…] | 取反,不能是括号中的任意单个元素 |
中括号[]代表多选一,可以表示里面的任意单个字符,所以任意元音字母可以用 [aeiou] 来表示。
中括号中,我们还可以用中划线表示范围,比如 [a-z] 可以表示所有小写字母。
如果中括号第一个是脱字符(^),那么就表示非,表达的是不能是里面的任何单个元素。
比如资源可能以 http:// 开头,或者 https:// 开头,也可能以 ftp:// 开头,那么资源的协议部分,可以使用 (https?|ftp):// 来表示。
贪婪、非贪婪与独占模式
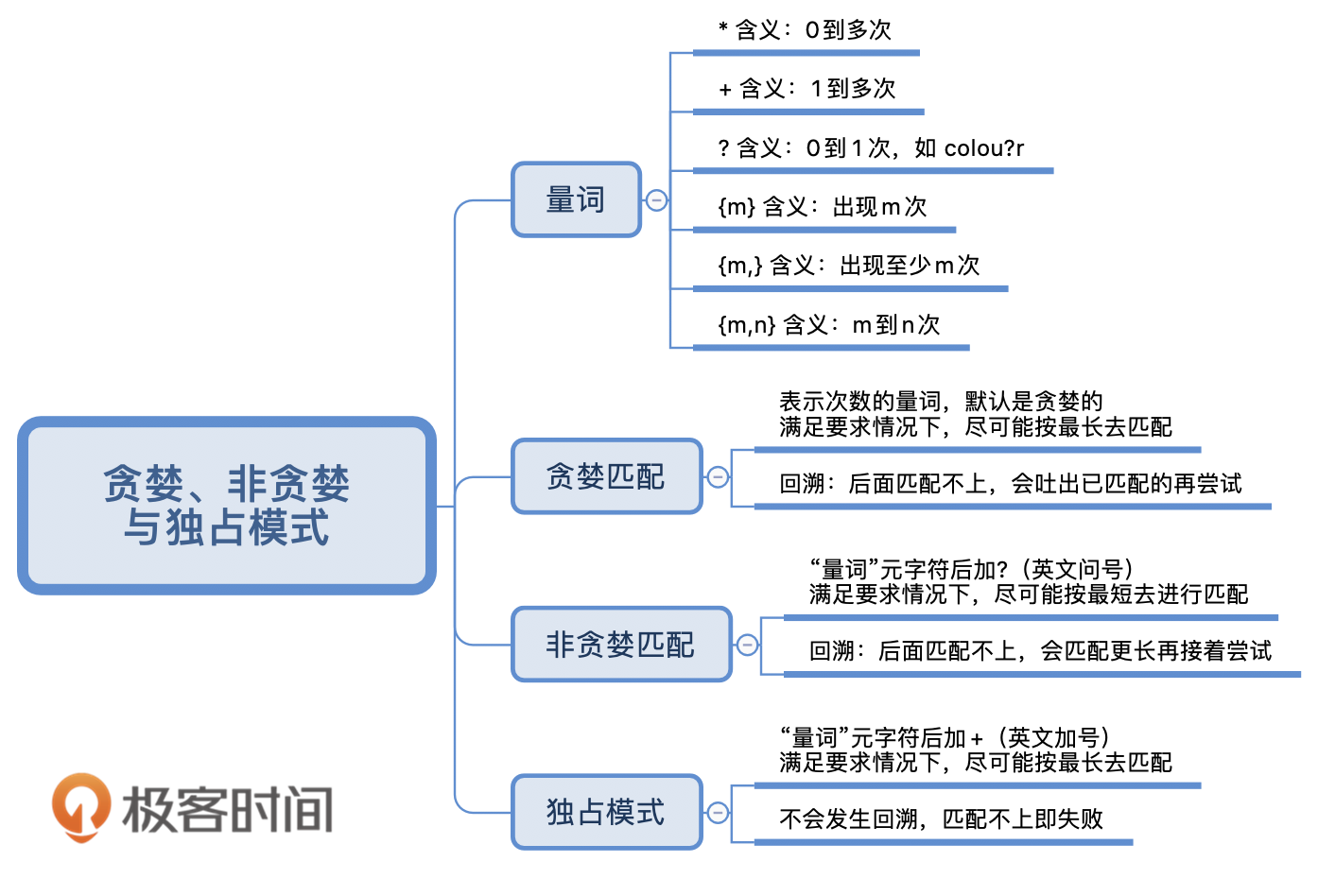
- 贪婪匹配
尽可能进行最大长度匹配。表示次数的量词,默认是贪婪的,默认尽可能多地去匹配。
- 非贪婪匹配
尽可能进行最短匹配。“量词”元字符后加 ? , 是非贪婪的,尽可能最短地去匹配。
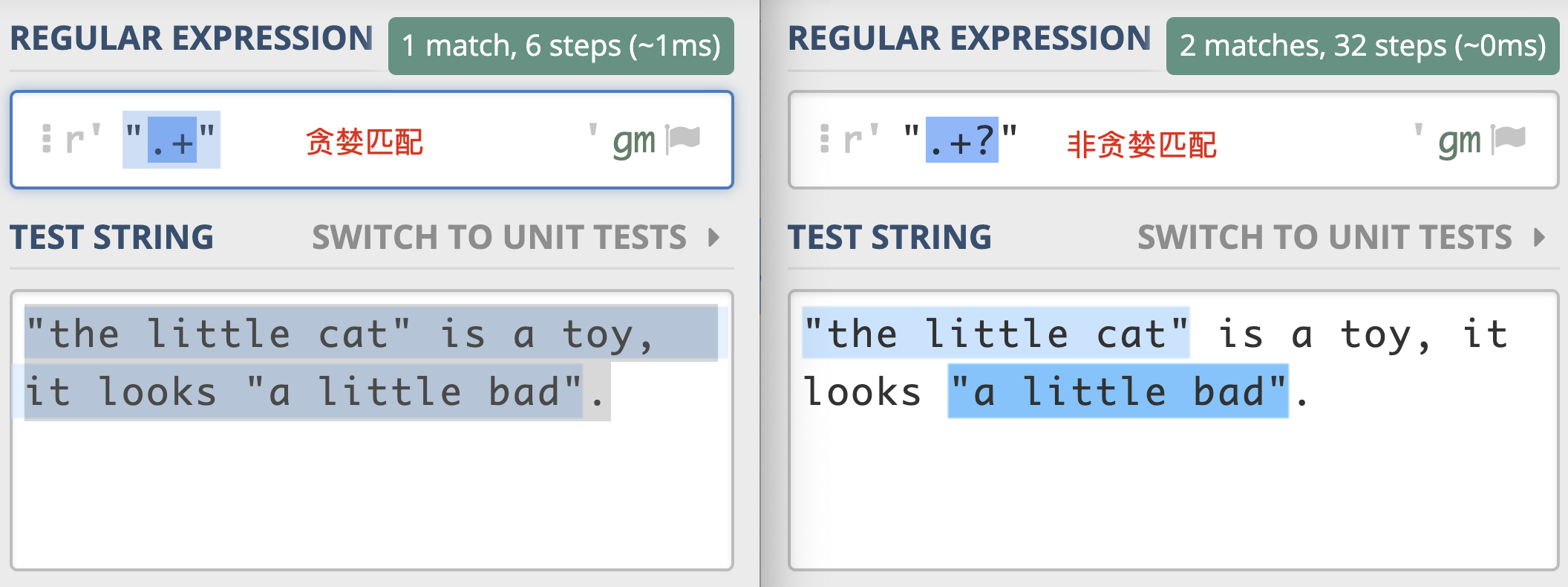
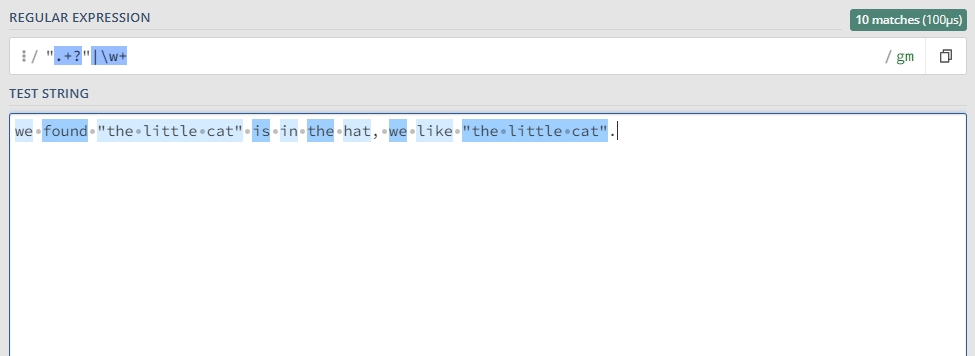
左边的示例中,不加问号时正则是贪婪匹配,匹配上了从第一个引号到最后一个引号之间的所有内容;
右边的示例中,加问号时正则是非贪婪匹配,找到了最短长度的符合要求的内容;
- 独占模式
不管是贪婪模式,还是非贪婪模式,都需要发生回溯才能完成相应的功能。
贪婪模式下的回溯,比如 regex = “xy{1,3}z” text = “xyyz”, 在匹配时,y{1,3}会尽可能长地去匹配,当匹配完 xyy 后,由于 y 要尽可能匹配最长,即三个,但字符串中后面是个 z 就会导致匹配不上,这时候正则就会向前回溯,吐出当前字符 z,接着用正则中的 z 去匹配,匹配成功。
非贪婪模式下的回溯,比如 regex = “xy{1,3}?z” text = “xyyz”, 在匹配时, 由于 y{1,3}? 代表匹配 1 到 3 个 y,尽可能少地匹配。匹配上一个 y 之后,也就是在匹配上 text 中的 xy 后,正则会使用 z 和 text 中的 xy 后面的 y 比较,发现正则 z 和 y 不匹配,这时正则就会向前回溯,重新查看 y 匹配两个的情况,匹配上正则中的 xyy,然后再用 z 去匹配 text 中的 z,匹配成功。
但是在一些场景下,我们不需要回溯,匹配不上返回失败就好了,因此正则中还有另外一种模式,独占模式,它类似贪婪匹配,但匹配过程不会发生回溯,因此在一些场合下性能会更好。 独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,具体的方法就是在量词后面加上加号(+)。比如 regex = “xy{1,3}+yz” text = “xyyz”, y{1,3}+尽可能多地匹配了两个 y , 不回溯导致正则 z 前面的 y 匹配不上。
案例
有一篇英文文章,里面有很多单词,单词和单词之间是用空格隔开的,在引号里面的一到多个单词表示特殊含义,即引号里面的多个单词要看成一个单词。现在你需要提取出文章中所有的单词。我们可以假设文章中除了引号没有其它的标点符号,有什么方法可以解决这个问题呢?如果用正则来解决,你能不能写出一个正则,提取出文章中所有的单词呢(不要求结果去重)?
-
文章
we found “the little cat” is in the hat, we like “the little cat”. 其中 the little cat 需要看成一个单词好了。
分组与引用
括号在正则中的功能就是用于分组。简单来理解就是,由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示一个整体,这是括号的一个重要功能。其实用括号括起来还有另外一个作用,那就是”复用”。
- 分组
括号在正则中可以用于分组,被括号括起来的部分”子表达式”会被保存成一个子组。
分组与编号
那分组和编号的规则是怎样的呢?其实很简单,用一句话来说就是,第几个括号就是第几个分组。

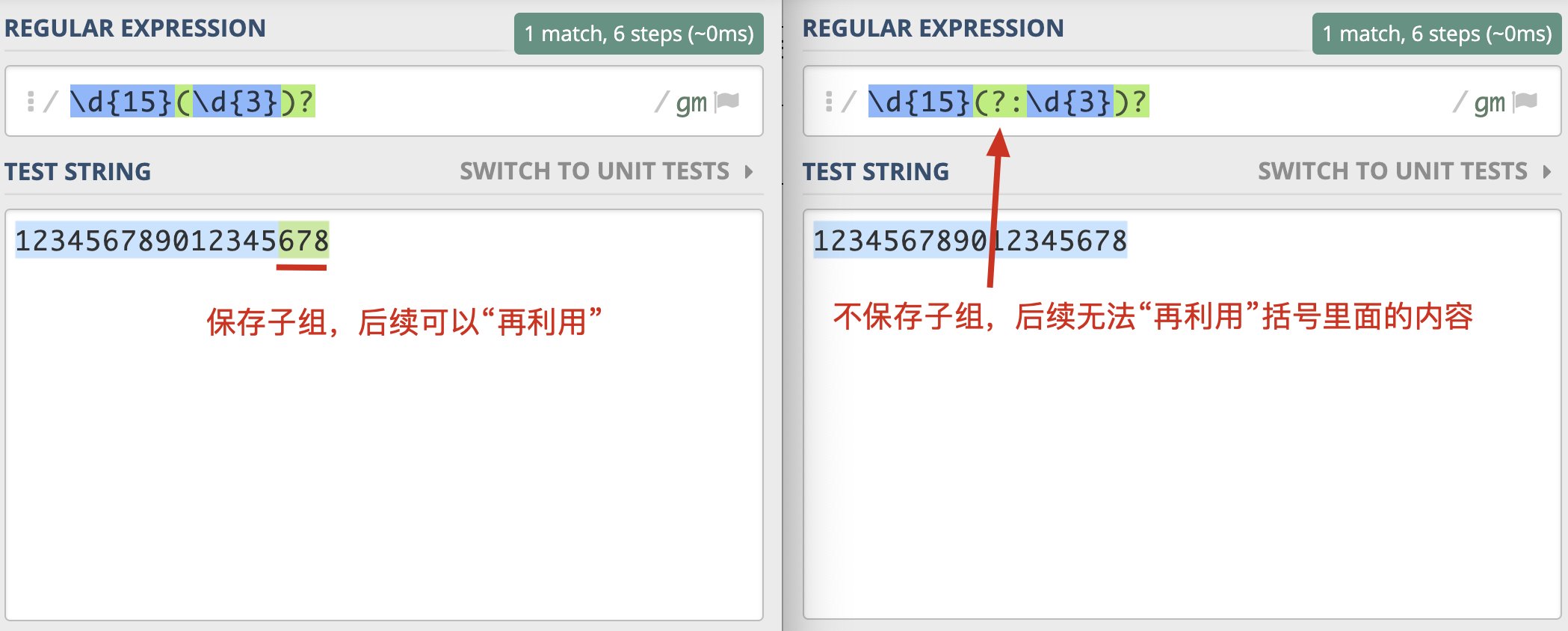
不保存子组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,我们可以在括号里面使用 ?: 不保存子组。
括号嵌套
在括号嵌套的情况里,要看某个括号里面的内容是第几个分组怎么办?其实方法很简单,我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。

- 引用
在知道分组编号后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即 \number 的方式来进行引用, JavaScript 中是通过$编号来替换,如$1。
| 标识 | 查找时引用方式 | 替换时引用方式 |
|---|---|---|
| Python | \number,如 \1 | \number,如 \1 |
| Go | 官方包不支持 | 官方包不支持 |
| JavaScript | \number,如 \1 | $number,如 $1 |
- 分组引用在替换中使用
案例
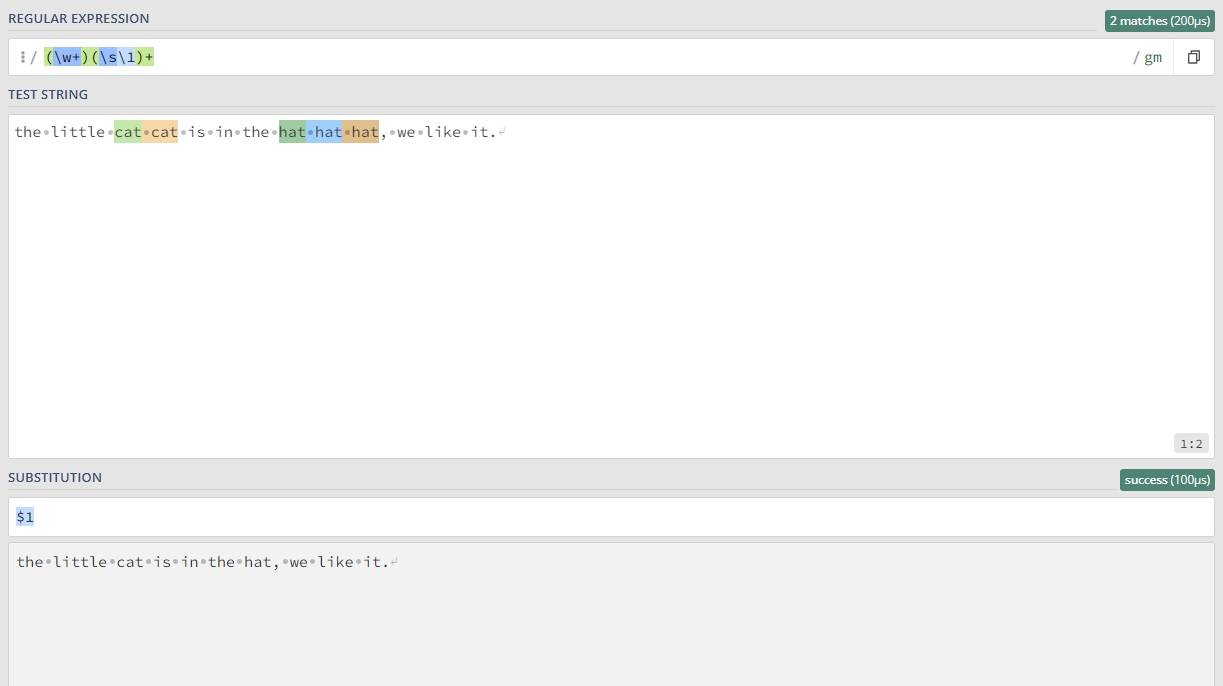
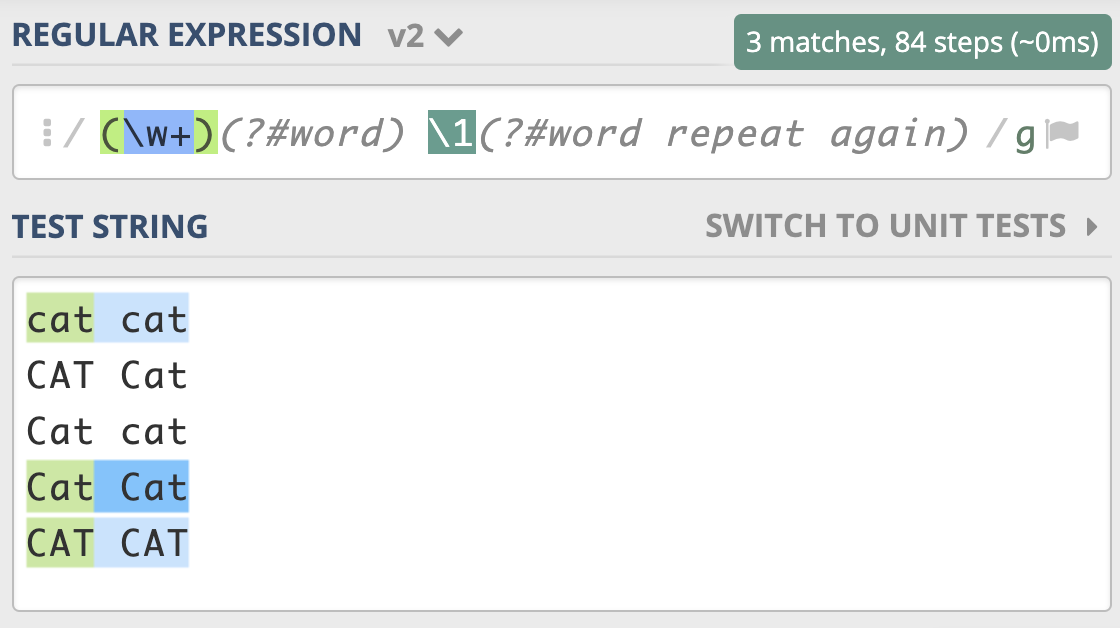
有一篇英文文章,里面有一些单词连续出现了多次,我们认为连续出现多次的单词应该是一次,比如:The little cat cat is in the hat hat hat, we like it. 要求处理后的结果是 The little cat is in the hat, we like it.
正则表达式匹配模式
模式修饰符是通过 (? 模式标识) 的方式来表示的。 我们只需要把模式修饰符放在对应的正则表达式前,就可以使用指定的模式了。
- 不区分大小写模式(Case-Insensitive)
在不区分大小写模式中,由于不分大小写的英文是 Case-Insensitive,对应的修饰符是 (?i) 。
案例1
匹配两个连续出现的 cat,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上。
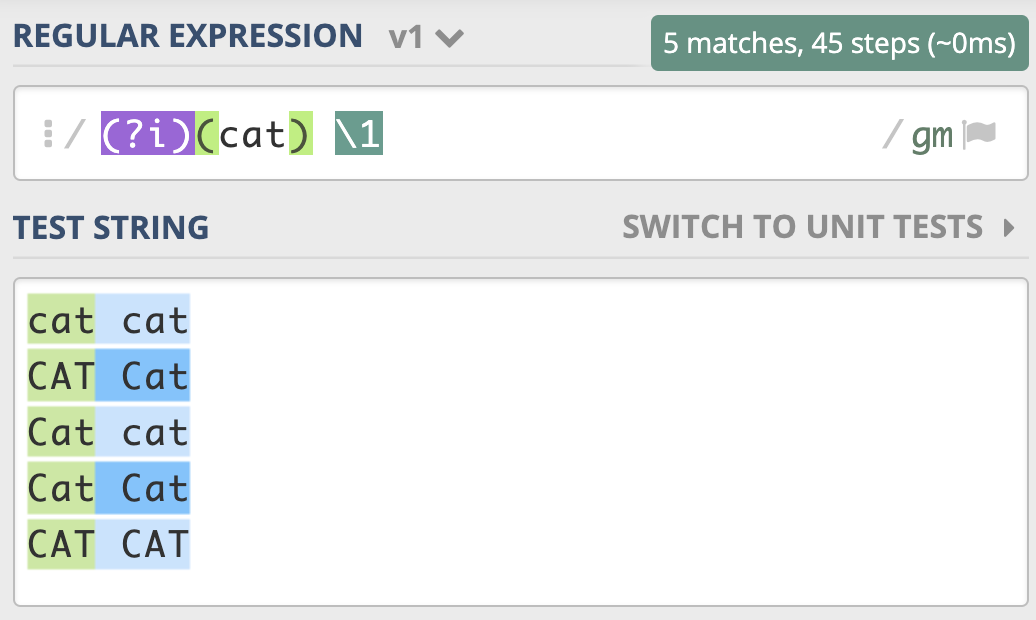
匹配两个连续出现的 cat,即便是第一个 cat 和第二个 cat 大小写不一致,也可以匹配上。
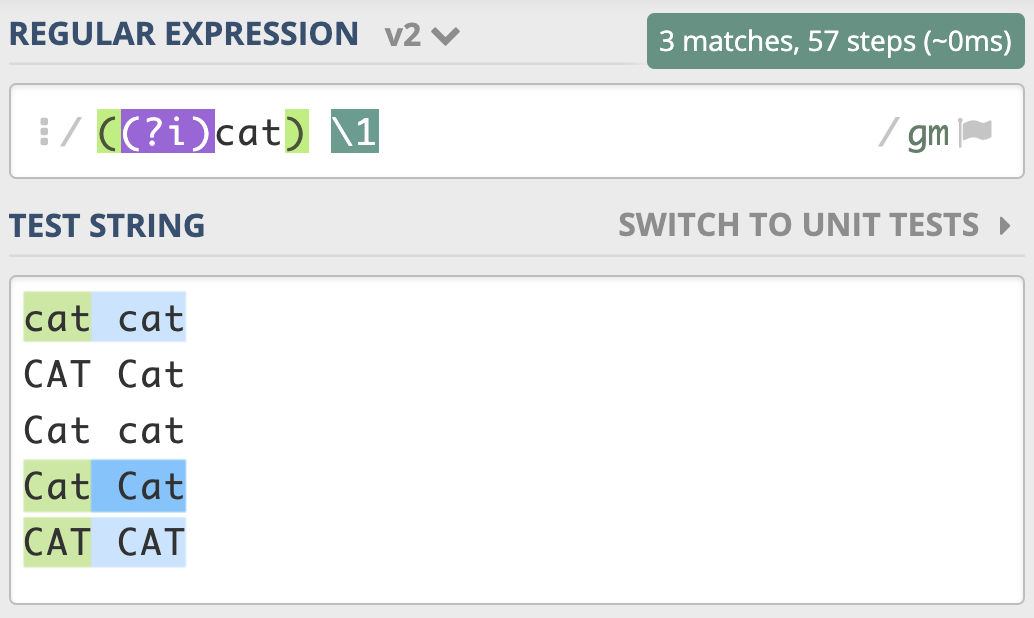
案例2
如果想要前面匹配上的结果,和第二次重复时的大小写一致,只需要用括号把修饰符和正则 cat 部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里的内容。
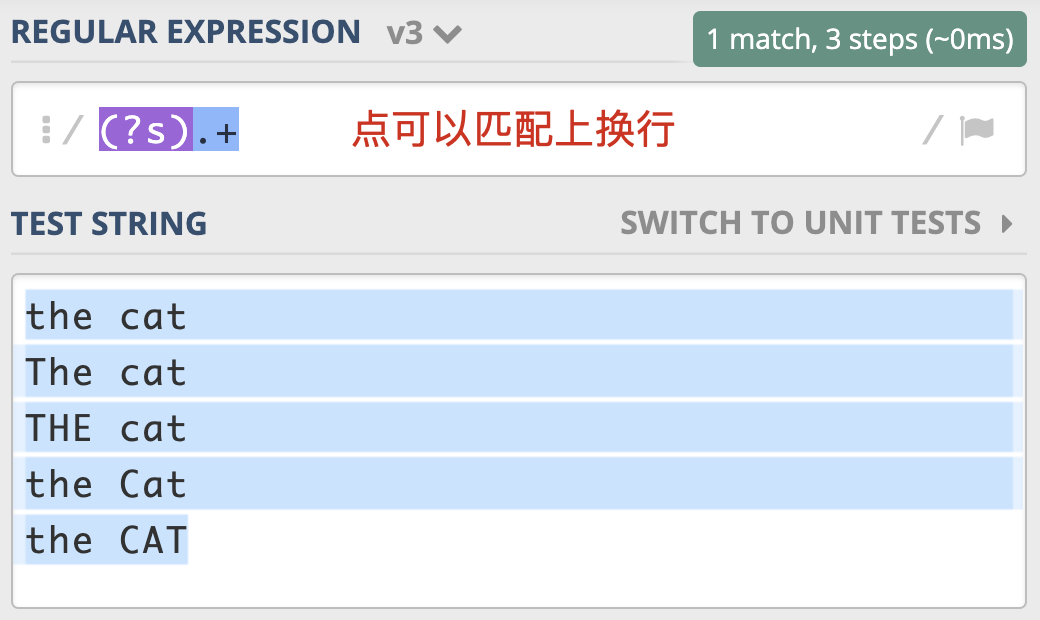
- 点号通配模式(Dot All)
你还记得英文的点(.)有什么用吗?它可以匹配上任何符号,但不能匹配换行。当我们需要匹配真正的”任意”符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。但是这么写不够简洁自然,所以正则中提供了一种模式,让英文的点(.)可以匹配上包括换行的任何字符。这个模式就是点号通配模式,对应的修饰符是 (?s) 。
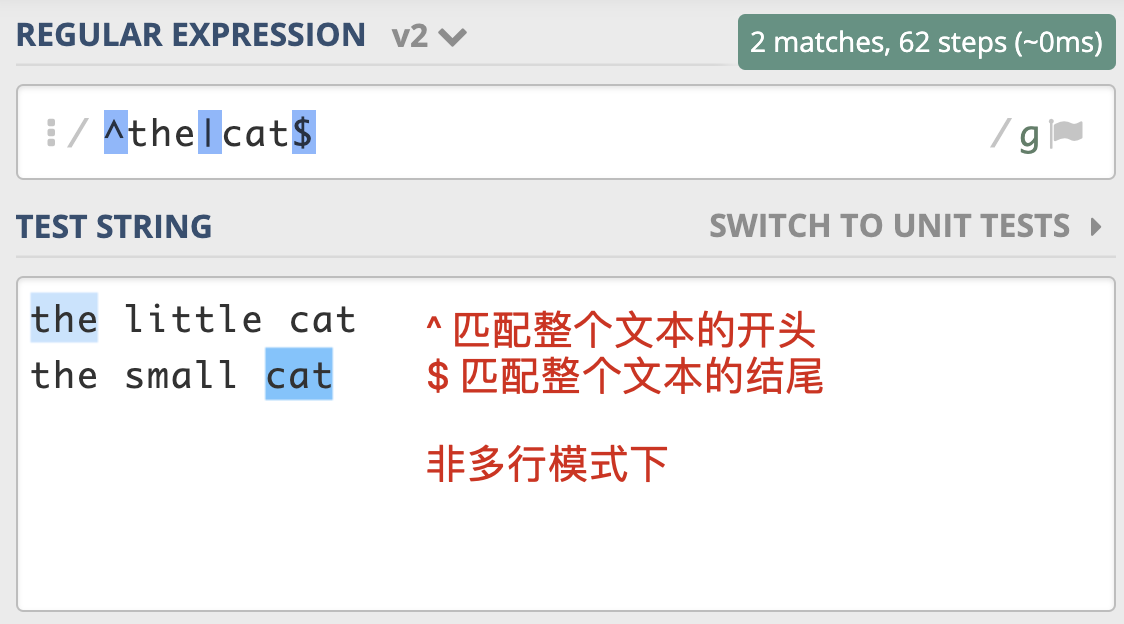
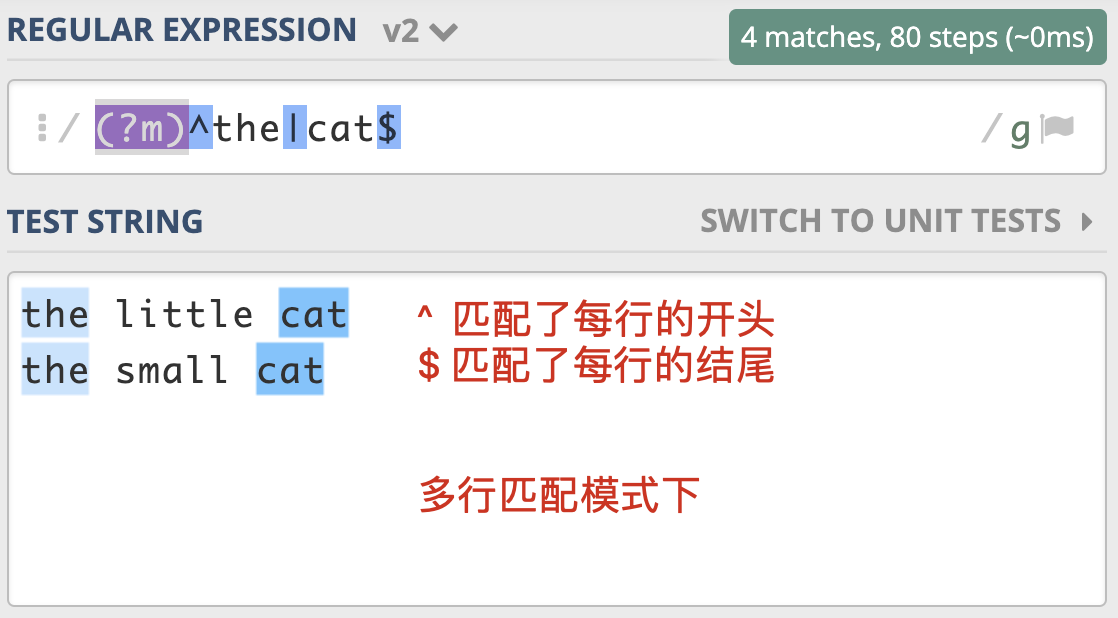
- 多行匹配模式(Multiline)
通常情况下,^匹配整个字符串的开头,$ 匹配整个字符串的结尾。多行匹配模式改变的就是 ^ 和 $ 的匹配行为,使 ^ 和 $ 能匹配上每行的开头或结尾,对应的修饰符是 (?m) 。
- 注释模式(Comment)
在实际工作中,正则表达式可能会很复杂,这就导致编写、阅读和维护正则都会很困难。很多语言也支持在正则表达式中添加注释,让正则更容易阅读和维护,这就是正则的注释模式。正则中注释模式是使用 (?#comment) 来表示。
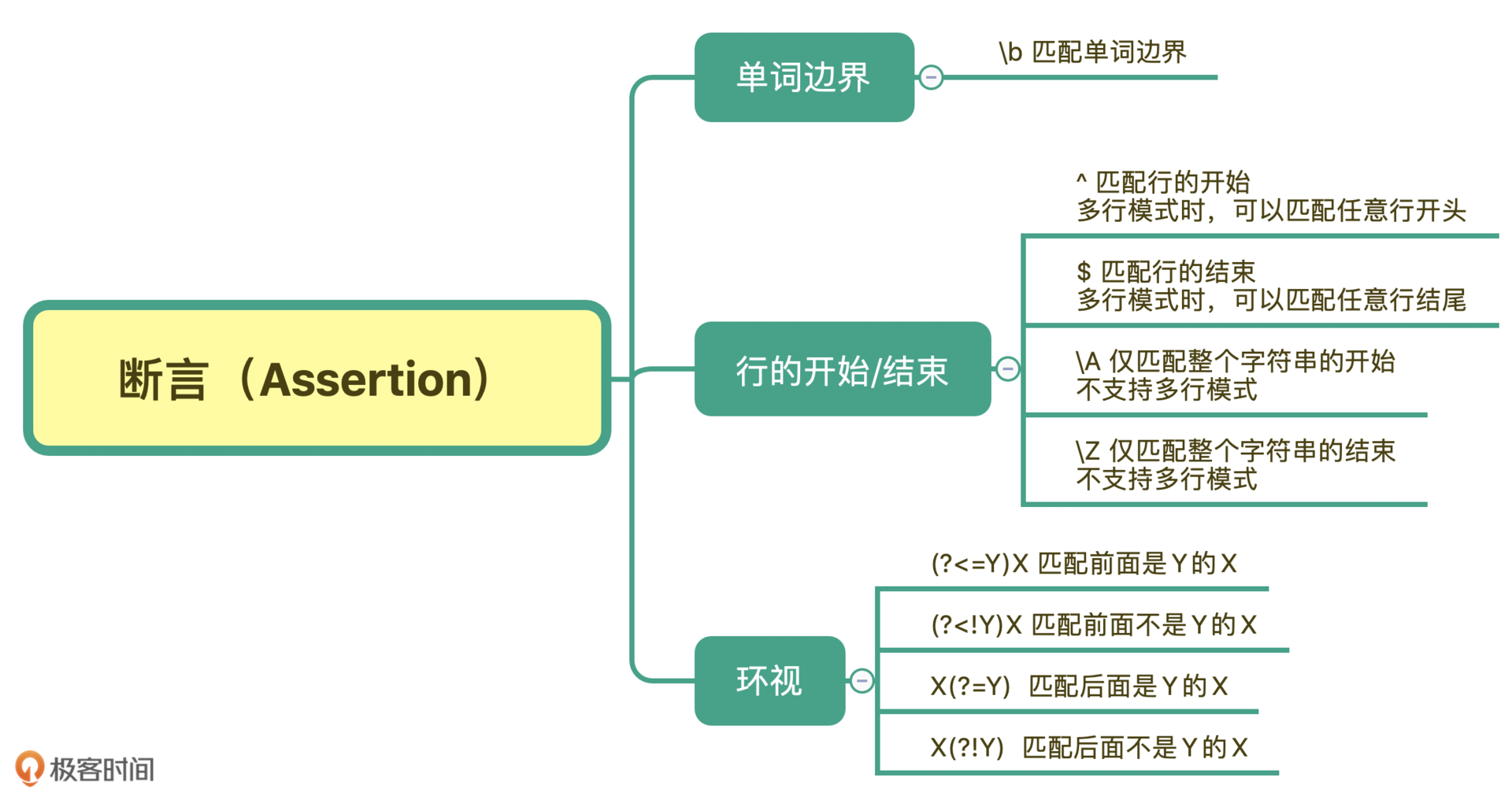
正则表达式断言
只用于匹配位置,而不是文本内容本身,这种结构就是断言。常见的断言有三种:单词边界、行的开始或结束以及环视。
- 单词边界(Word Boundary)
单词的组成一般可以用元字符 \w+ 来表示,\w 包括了大小写字母、下划线和数字(即 [A-Za-z0-9_])。那如果我们能找出单词的边界,也就是当出现了\w 表示的范围以外的字符,比如引号、空格、标点、换行等这些符号,我们就可以在正则中使用 \b 来表示单词的边界。
- 行的开始或结束
和单词的边界类似,在正则中还有文本每行的开始和结束,如果我们要求匹配的内容要出现在一行文本开头或结尾,就可以使用 ^ 和 $ 来进行位置界定。
- 环视
在正则中我们有时候也需要瞻前顾后,找准定位。环视就是要求匹配部分的前面或后面要满足(或不满足)某种规则。
| 标识 | 查找时引用方式 | 替换时引用方式 |
|---|---|---|
| (?<=X>) | 肯定逆序环视 | 左边是X |
| (?<!X>) | 否定逆序环视 | 左边不是X |
| (?=X>) | 肯定顺序环视 | 右边是X |
| (?!X>) | 否定顺序环视 | 右边不是X |
口诀:左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
单词边界用环视表示
表示单词边界的 \b 如果用环视的方式来写,应该是怎么写呢?单词可以用 \w+ 来表示,单词的边界其实就是那些不能组成单词的字符,即左边和右边都不能是组成单词的字符。(?<!\w) 表示左边不能是单词组成字符,(?!\w) 右边不能是单词组成字符,即 \b\w+\b 也可以写成 (?<!\w)\w+(?!\w) , 但是不能写成 (?<=\W)\w+(?=\W) ,因为\W 不能匹配行开关和结尾 。
环视与子组
环视中虽然也有括号,但不会保存成子组。保存成子组的一般是匹配到的文本内容,后续用于替换等操作,而环视是表示对文本左右环境的要求,即环视只匹配位置,不匹配文本内容。